Why Ragas?Copied!
In a sea of options, it can be hard to decide on the right option to use for your evaluation needs. There are various tools like TruLens, promptfoo, Arize AI, deepchecks, deepeval and more, but there is one framework that stood out to us, and that is Ragas. Why Ragas? While you can simply choose either one of the aforementioned tools and get the insights and evaluations you need, there are multiple factors to consider when making your choice. Some of these are ease of implementation, integrability with other tools, scalability, the ability to add custom metrics, test set generation, etc.
Ragas is quite simple to implement (once you have a test set, setting up a simple evaluation chain takes as much time as it takes you to dig up your OpenAI API key), offers integration options with various other tools and has features such as automatic prompt adaptation and synthetic test data generation. If some of these terms are unfamiliar to you, worry not, we’re diving deeper into them right away.
What is Ragas?Copied!
We mentioned some features that Ragas offers, but what is Ragas exactly? The term ragas is an acronym meaning retrieval augmented generation assessment and to quote the Ragas team:
"Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines”
It’s developed and regularly updated by a small team called Exploding Gradients and if you have any questions or want to discuss RAG evaluation you can check out their Discord on which they are pretty active.
The main point of Ragas is to facilitate the so called metric-driven development. Metric-driven development is a paradigm that relies on continuous monitoring of metrics and collecting data in order to make informed decisions in product development. They aim to achieve this by offering evaluation of the core concepts that we discussed in the previous article, measuring, monitoring and improving each metric individually but also combining them all into one overarching metric they call the ragas score.
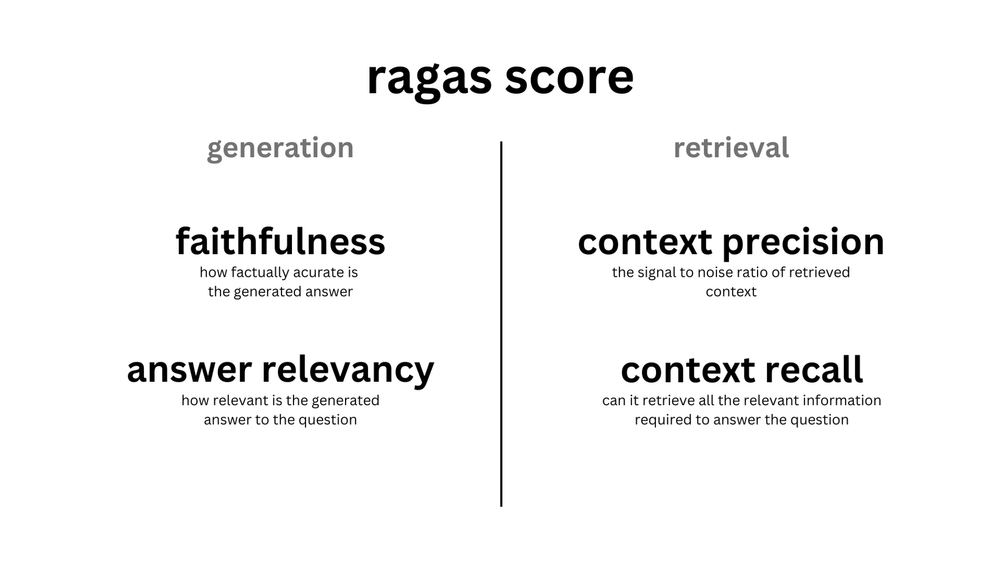 Images taken from official Ragas documentation
Images taken from official Ragas documentation
The ragas score is the harmonic mean (if you don’t know what a harmonic mean is, that’s fine, neither did I, just think of it as a more accurate average) of the 4 metrics outlined in the image above and is meant to give you an overall score value of the performance of your application. With that being said, you shouldn’t rely purely on the ragas score to evaluate your app, but rather use it as a guide keeping you on the right path while you work on improving each of the individual metrics.
Ragas also offers what they call end-to-end evaluation metrics: answer semantic similarity and answer correctness. These metrics focus exclusively on comparisons between the ground truth and the generated answer. Answer semantic similarity measures how alike in their meaning the generated answer and ground truth are and provides valuable insight into the quality of the generated response. Answer correctness does exactly what it sounds like it does, it looks at the accuracy of the generated answer when compared to the ground truth. It achieves this by looking at both the semantic similarity of the ground truth and the generated answer combined with factual similarity. Both of these metrics provide a good insight into the overall performance of your application but are not something you absolutely must use in your evaluation.
All of the metrics Ragas uses are measured on a scale between 0 and 1, with higher values meaning better performance. If you would like to know in depth how these metrics are calculated you can check out the official Ragas documentation where they provide a pretty comprehensive insight into their inner workings.
Additional featuresCopied!
What makes Ragas a really efficient choice for your evaluation needs is the fact that evaluation is not the only feature it offers. Two great features that are also included in the Ragas framework are synthetic test data generation and automatic prompt adaptation.
Why synthetic test data generation? In order to be able to evaluate your RAG application you’re going to need an extensive set of QCA (question, context, answer) pairs. Obtaining this set can be quite resource and time intensive if done manually. This is where synthetic test data generation comes in as a godsend. But wait, how can we be sure we’re getting quality data? Well, Ragas has quite a smart solution to this. To quote the team again:
"Inspired by works like Evol-Instruct, Ragas achieves this by employing an evolutionary generation paradigm, where questions with different characteristics such as reasoning, conditioning, multi-context, and more are systematically crafted from the provided set of documents."
What this means in simple terms is that each question that is generated goes through several iterations in order to ensure that the generated result is of the best quality that it can be. This approach vastly improves the quality of generated data and also reduces the time required for the data aggregation process by 90% (if this doesn’t sound all that impressive to you, just imagine going through ALL of your documents and thinking of questions to ask about them). Of course, it’s always a good idea to have a human look over the generated data to correct any potential errors. Again for a more in-depth insight check out the official docs on this topic.
Automatic prompt adaptation is a phrase that basically signifies the internationalisation of the prompts that Ragas uses under the hood while generating and evaluating test data. Pfft big deal, you might say. Yes, big deal. Due to the vast majority of LLMs being trained on data in the English language, they are known to perform noticeably worse when met with any other language. What the Ragas team found through experimentation is that if you provide examples and demonstrations in the target language to the LLMs, they can adapt much better and produce significantly better results. So what automatic prompt adaptation allows us, is to use a much wider array of documents and avoid translating those documents to English in order to use them. In-depth insight here.
Data visualisationCopied!
By default, the result of evaluation is an object where the properties are the metrics you’ve chosen. You can export this result to a pandas dataframe and save it locally for a detailed overview of the scores across your whole dataset.

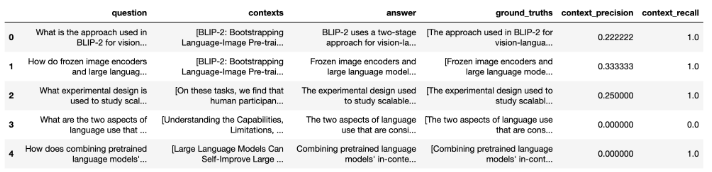 Images taken from official Ragas documentation
Images taken from official Ragas documentation
While this approach is good enough in most cases, another cool thing about Ragas is that it offers integration with various visualisation tools to give you a nicer overview of the results. The implementation of these integrations is explained quite nicely in their documentation, so if you’ve opted for using any of the technologies that they already have covered, you’re in luck. If you’ve however decided to go a different route, you can discuss options with them on their Discord or raise a Github issue , they are open to all kinds of suggestions.
If you’re interested in how we implemented our evaluation chain, stay tuned for an upcoming article on this topic.
Connecting metric data with actionsCopied!
Okay, now we know what the core metrics are and how to test for them with Ragas, but what do we do with that information? Well, we make changes to our application. The great thing about RAG applications is everything is interconnected, meaning if you make improvements in one metric, it’s likely that some of the others might improve as well.
For the sake of this example, let’s assume that you ran the evaluation on your application and you got underwhelming scores in all of the metrics. Let’s start with the retrieval metrics, and I mean that not only in this article but also when actually starting to make changes to your application. The reason for this is simple, better retrieved context equals in most cases better generated answers. First off, let’s look at context precision.
As we established in the previous article, context precision tells us the amount of useful vs useless information our context provides. So the first thing we’re going to try and change is our chunk size. You might have started with too big of a size and are getting way too much information in the context you’re providing to the LLM and are overwhelming it. In this case try smaller chunk sizes and see how that influences your score. The same applies to the inverse, you might have started off with too small of a size and might need to increase it. Okay, we got some better results in context precision, but our context recall is still quite low. So now we’re going to try a different retrieval strategy.
Let’s assume you started off with basic retrieval. The simplest potential improvement we can make here is try out sentence window retrieval, since it doesn’t require us to change our embeddings. Our retrieval scores improved quite a bit now, great. Our generation scores improved a little as a result of this, but are still quite low. The first thing we’re looking at here is our prompts. The way you present your context and request generated answers from your LLM of choice is going to greatly influence the quality of your results. So much so that there is a whole paradigm called prompt engineering dedicated to making the best possible prompts you can supply to your LLM of choice. You’ve now made the best prompts in the world, but your scores are still not quite where you want them to be. Well, it might be time to look into some different models for generation. You tried a different model and all your scores now look great, congratulations you’ve made your RAG application production ready.
The key thing to note here is that the process I’ve laid out here is not to be taken as the best or default way to go about making changes to your application. You’re going to have to play around. The scores every developer gets for their RAG application are almost certainly going to be different. So you’re just going to have to go by feel, try things out that make sense to you, and if you’ve missed, try again until you’ve come to a score that you’re satisfied with and your application is the best version of itself that it can be.
ConclusionCopied!
The options for meeting your evaluation needs are many, and choosing the right one for you depends on which factors you value the most. Ragas, though currently in it’s early stages, is already coming up as a major player in the world of RAG application evaluation. Regularly updated, connected with its user base, offering additional features and integrations, it’s definitely a tool worth investigating and keeping your eye on as it develops further.
SummaryCopied!
In this article you learned that Ragas is a framework that helps you evaluate your RAG applications, you learned about the metrics it employs to evaluate RAG applications, and you learned why the additional features it offers like synthetic test data generation and automatic prompt adaption are great additions to an evaluation framework. You also learned how to simply view the results of your evaluation and also that you can integrate those results with tools that visualize them for you. The most important thing this article showed you is what you can actually do with the results you get and how to make your application the best it can be. Now that you’re armed with all this knowledge, I wish you happy evaluating.